Big Data und KI
Künstliche Intelligenz und Big Data sind zwei Schlüsseltechnologien, mit der Sie innovative Lösungen in verschiedenen Bereichen ermöglichen können. Gerade in der Informationsforschung ist die Auswertung von Daten relevant.
In diesem Beitrag erläutere ich ein paar Anwendungen.

Informationswissenschaft und Big Data?
Die Informationswissenschaft ist ein Studienbereich, der sich mit der Untersuchung und Analyse der Datenerfassung und -verarbeitung befasst. Dieser Bereich gewährleistet die Effizienz, Zuverlässigkeit und Sicherheit von Informationssystemen, was in unserer datengesteuerten Welt von entscheidender Bedeutung ist. Der Begriff "Big Data" bezieht sich auf die enorme Menge an Daten, die in jeder Sekunde produziert wird. Die Informationswissenschaft ist heute in der Lage, diese grossen Datenmengen zu verwalten und zu manipulieren. Mit Hilfe von Big Data kann die Informationswissenschaft einer Organisation helfen, Erkenntnisse zu verwalten, Entscheidungen auf der Grundlage von Fakten zu treffen und insgesamt effektiver zu sein.
Was ist Big Data?
Künstliche Intelligenz (KI) und Big Data sind zwei der wichtigsten technologischen Entwicklungen unserer Zeit. Sie bilden die Grundlage für zahlreiche Innovationen und Fortschritte in verschiedenen Bereichen wie Gesundheitswesen, Finanzwesen, Marketing und vielen anderen. Wir erläutern eben, wie KI-Modelle und Big Data funktionieren und wie sie miteinander interagieren, um leistungsstarke Anwendungen zu ermöglichen.
WICHTIG! Die vier V`s
Volumen:
Die grosse/wachsende Menge der erzeugten und gespeicherten Daten ist enorm und stellt eine Herausforderung für die Speicherung und Verarbeitung dar.
Varietät:
Big Data stammt aus verschiedenen Quellen und liegt in unterschiedlichen Formaten vor, z.B. strukturierte, semi-strukturierte und unstrukturierte Daten.
Geschwindigkeit (Velocity):
Die Geschwindigkeit, mit der Daten erzeugt und verarbeitet werden müssen, ist hoch. Echtzeit-Analysen sind oft erforderlich, um zeitnahe Entscheidungen zu treffen.
Veracity (Wahrhaftigkeit):
Die Qualität und Zuverlässigkeit der Daten variieren. Eine gründliche Datenbereinigung und Sicherstellung der Datenintegrität sind entscheidend.
Künstliche Intelligenz (KI) benötigt Big Data
Aktuell ist das Jahr 2024 und die technologische Errungenschaft, die in aller Munde ist, ist die Künstliche Intelligenz (KI). Die meisten KI-Modelle sind neuronale Netze (NN), die mit Referenzdaten trainiert werden, um Vorhersagen über die nächsten Wörter, Zahlen oder Pixel für ein Bild zu treffen (GenAI). Daher ist der Begriff "neuronales Netz" passender als "künstliche Intelligenz", da eine selbstständige Handlungsfähigkeit und das eigenständige Herleiten von Ergebnissen derzeit noch in der Zukunft liegen.
Für das Training der NN werden Daten benötigt, die nach den vier V's der Big Data kategorisiert werden, um die richtige Balance zu erreichen: Volumen, Vielfalt, Geschwindigkeit und Verlässlichkeit (Volume, Variety, Velocity, Veracity). Aufgrund der Komplexität der Themen möchte ich auf Oracle.com verweisen, da dort viele Dinge über Big Data bereits detailliert erklärt wurden.
Daher fasse ich mich jetzt ein bisschen kürzer...
Training von Modellen
Grosse Datenmengen stellen sicher, dass die KI-Modelle eine breite Palette von Szenarien und Variationen lernen können. Dies verbessert die Generalisierungsfähigkeit des Modells auf neue, unbekannte Daten. Sollte die Vielfalt der Daten nicht vorhanden sein oder Daten fehlen, kann diese mit Hilfe der Imputation-Methode auffüllen.
Mit einer grossen Datenmenge ist die Wahrscheinlichkeit geringer, dass das Modell nur spezifische Muster in den Trainingsdaten lernt (Overfitting). Stattdessen lernt es, allgemeinere Muster zu erkennen, die auf verschiedene Datensätze anwendbar sind.
Feinabstimmung der Modelle: Mehr Daten ermöglichen eine präzisere Abstimmung der Modelle. Dies führt zu einer besseren Leistung und Genauigkeit bei Vorhersagen oder Klassifikationen.
Bessere Fehlererkennung: Grosse Datensätze enthalten in der Regel mehr Fehlerfälle und Ausnahmen, die das Modell lernen kann, was zu robusteren und zuverlässigeren Vorhersagen führt.
Anwendung auf verschiedene Domänen: Mit grossen und vielfältigen Datenmengen können KI-Modelle auf unterschiedliche Anwendungsbereiche skaliert und angepasst werden, sei es in der Medizin, im Finanzwesen oder im Transportwesen.
Erkennung subtiler Muster: Bestimmte Muster oder Zusammenhänge sind nur in grossen Datenmengen erkennbar. Big Data ermöglicht es, diese subtilen Muster zu erkennen und zu nutzen.
Lernverfahren KI
KI-Anwendungen können von vordefinierten Antworten, bis hin zu komplexen Systemen wie autonomes fahren reichen. Daher unterscheiden wir auch in der Tiefe die Typen.
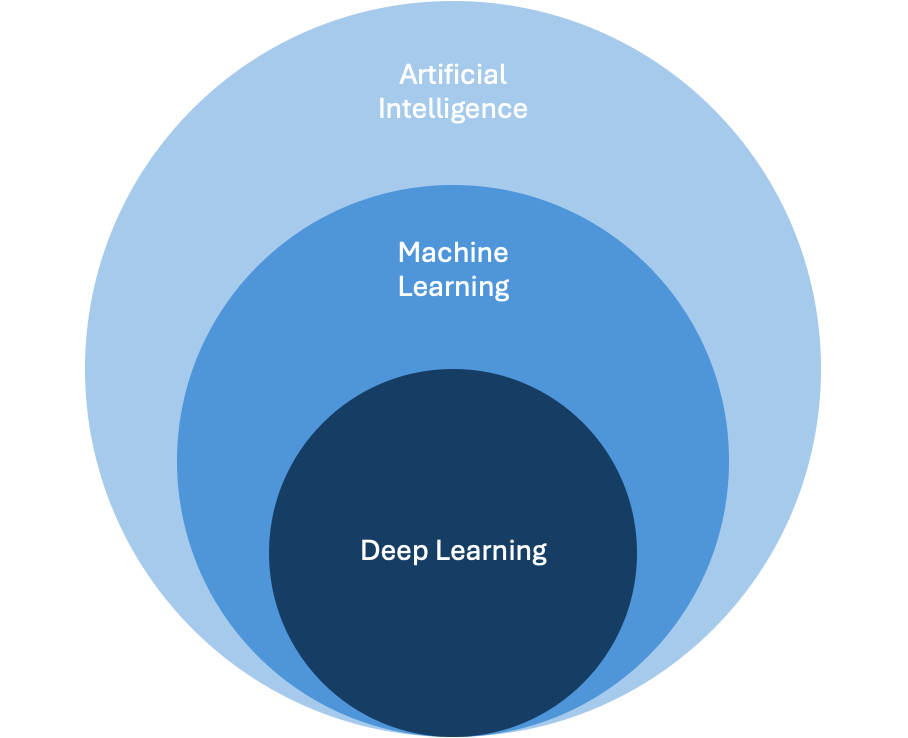
Unterscheidung von künstlicher Intelligenz
Artifical Intelligence
befasst sich mit der Automatisierung intelligenten Verhaltens und dem maschinellen Lernen.
Machine Learning ist ein Teilbereich der
künstlichen Intelligenz und generiert Wissen aus Erfahrung. Ein ML-System lernt aus Beispielen und kann diese verallgemeinern.
Deep Learning ist eine Teilmenge von ML,
welches sich auf künstliche neuronale Netze und grosse Datenmengen fokussiert.
Lernmethoden der künstlichen Intelligenz
Ein wichtiger Punkt zur Unterscheidung von Künstlicher Intelligenz ist die Art des Lernens. Manche KI-Modelle sind durch ihre Lernmethode bereits auf gewisse Bereiche beschränkt und können je nach Anwendung für uns ein Ausschlusskriterium sein.
Reinforcement Learning
Lernen über Belohnung und Bestrafungen. Das Ziel ist es, eine Strategie zu entwickeln, um die Gesamtbelohnung zu maximieren.
Deep Learning
Maschinelles Lernen mit neuronalen Netzen. Ziel ist es komplexe Muster in grossen Datenmengen zu erkennen.
Transfer Learning
Ein Model welches zuvor einen ähnlichen Zweck hatte, wird neu trainiert.
Beispiel: Ein KI-Modell, welches ursprünglich Autos erkennen sollte, kann angepasst werden, um Motorräder zu erkennen.
Supervised Learning
Häufige Lernmethode. Das Modell lernt aus einem Datensatz, der sowohl Eingaben als auch
die dazugehörigen Ausageben enthält. Ziel ist es Muster in den zu erkennen, um Vorhersagen und Klassifikationen für neue, unbekannte Daten zu machen.
Unsupervised Learning
Das KI-Modell soll Strukturen oder Muster in den Daten selbst finden ohne Eingaben und Ausgaben zu erhalten.